In This Economy: Why Your AI Agent Stack is a $3,500 Financial Time Bomb
I almost dropped a grand on tokens on a Tuesday night. Your AI agents are quietly bleeding you dry. Learn how to build a Pragmatic Stack to stop the API tax and regain your data sovereignty.
I almost dropped a grand on a Tuesday night. Not on a mountain bike or a last-minute trip—on tokens. My agents were chatting away, and they were billing me for every single word of their "brainstorming" session.
I sat staring at API usage charts at 2 AM. The lines were climbing up and to the right with the kind of vertical spike that makes VCs cheer and developers sweat.
I wasn't cheering. I was doing the mental math, multiplying fractions of a cent by millions of tokens, and realizing I’d built a machine that was quietly bleeding me dry.
That Tuesday night was a wake-up call. I thought I was being efficient. I wasn't. I was just leaking cash through a hole in my automation strategy. I saw a $42 spike in three hours. On that trajectory, I was looking at a $1,000 bill by the weekend. I’d set up this beautiful, capable multi-agent harness. Agents talking to agents. They were monitoring systems, summarizing my voice notes, and brainstorming in the background. It felt like the future.
Then I looked at the Google AI Studio dashboard.
In this economy, that's just plain financial suicide.
Y'all, we are rushing to automate everything. I see delivery leaders and executives handing out top-tier LLM keys like candy, thrilled that the team is shipping more. But we’re treating these autonomous systems like a standard SaaS subscription. They aren't. They’re a utility, like water or the power bill. If you leave the tap running with a premium model, you’re going to flood your budget.
I had to rethink my whole approach. I wanted the power of an agentic workflow, but I refused to pay the "API tax" on every single automated thought.
Here is what I learned about the hidden costs of AI automation, and how I built a local, pragmatic stack to stop the bleeding.
The Exponential Cost of a "Faster Hammer"

We were promised AI would make us faster. For discrete tasks, writing an email or drafting a user story, it does. But the game has changed. We aren't just prompting chatbots anymore. We’re launching agents.
Agents operate continuously. They run "heartbeats." They poll databases to see if conditions changed. They engage in multi-agent sessions where one model critiques another in a loop.
When you apply an old-school tooling mindset to this, treating top-tier models like Claude Opus 4.7 or GPT 5.5 as your default hammer, you break the bank.
The numbers are ugly. In 2024, we worried about a $500 ChatGPT Plus bill for the department. Today, a single misconfigured agent harness can chew through $500 before your morning coffee is cold. NVIDIA’s Jensen Huang says his engineers should burn AI tokens worth half their salary every year. That’s easy for him to say—he’s the one selling the tokens. For those of us actually trying to ship software on a budget, that’s a recipe for bankruptcy.
As a delivery lead, if your budget is blown on tokens before the sprint is over, you’ve lost your experimentation runway. An unmanaged AI bill is more than a line item. It’s an impediment to the team’s sustainability.
This is basic queuing theory. As I wrote in The Future of Work, AI drastically increases the arrival rate of work. If your automated systems are generating a massive volume of background activity, and you’re paying a premium tax on every transaction, you are penalizing your own throughput.
You cannot run a continuous multi-agent harness on Claude Opus 4.7 or GPT 5.5. It is mathematically unsustainable for a team trying to prove ROI.
My $1,000 Liability and the Hardware Pivot
The story of my custom agent team is one where privacy and cost finally collided. I’ve been building a suite of tools to augment my daily workflow—agents that learn, improve, and process everything I feed them to make my coaching more effective.
Initially, I piped all of this through Gemini 3 Pro. But as the team grew, I realized I didn't want my private thoughts or sensitive documents sitting in someone else's training set. It wasn't just the money. It was about sovereignty. I realized that waiting an extra few seconds for a local machine to process a transcript was a trade-off I was happy to make to keep my data in-house.
I needed to move the sensitive tasks off the cloud.
I looked at my options. I’d bought a mini PC for my wife, thinking it would be a great desktop solution. She hated it. She wanted her Mac back, so I bought her a new Mac mini and inherited the hardware. It has 32GB of RAM and a solid processor. I wiped it. I installed Xubuntu.
I chose Xubuntu because I don't want to play SysAdmin. I want a box that sits in the corner and works while I'm coaching my team. Moving Ollama to that local Linux box gave me total data sovereignty and dropped my marginal cost for transcribing long-form voice notes to exactly $0.00. I can process ten hours of rambling thoughts, and it costs me nothing but electricity.
But privacy is only one pillar. To control the "financial time bomb," you need a strategy for the models themselves.
The Pragmatic Stack: Routing for ROI
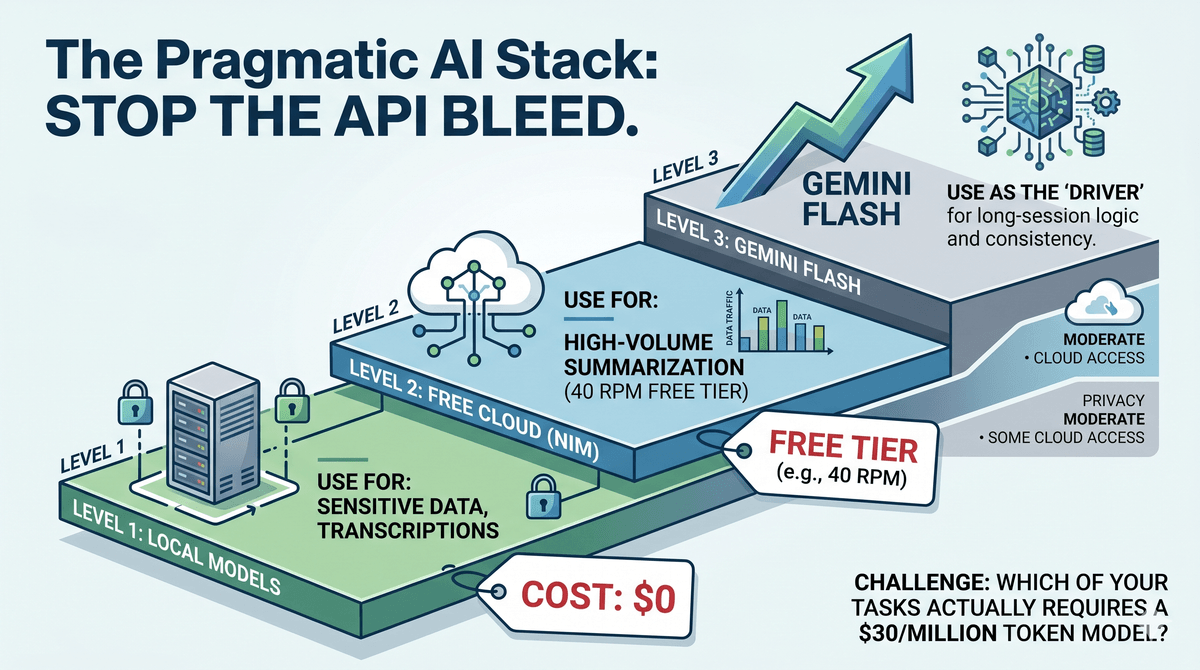
You do not need an omniscient, top-tier model to parse a JSON file or check a Jira ticket. Using GPT-5.5 for basic routing is like hiring a senior architect to sort your mail.
You need a Pragmatic Stack. This is a hybrid architecture that routes tasks based on complexity and cost.
1. Local Models for Privacy
For tasks involving sensitive client data, internal strategy, or raw Whisper transcriptions, I run local models on my Linux box.
A local Llama isn't as smart as GPT-5.5. It doesn't need to be. It just needs to transcribe my voice and format a list. Save the high-IQ models for the architectural heavy lifting. This ensures the most "human" parts of my agentic workflow never leave my four walls.
2. Free and Cheap Cloud Models for Cost Efficiency
If you’re running agents, you quickly discover that local hardware bottlenecks are the real hurdle. This is why I use NVIDIA NIM models (available at build.nvidia.com). While NIM is a hosted service, they offer a generous free tier of 40 Requests Per Minute (RPM) and incredible throughput.
You can use Llama 3.1 70B on NIM to replace a cloud-based summarization task. It’s fast, and the 40 RPM free tier is plenty for a pilot. For everything else that doesn't require high-end reasoning, I use OpenRouter to access the cheapest possible inference for the connective tissue of my workflows.
3. Google Gemini for Consistency
NIM and local models are great, but for the "driver" of the harness—the agent that needs to maintain logic across a long session—I use Google Gemini (specifically 3 Flash). It’s my number one driver for speed and consistency. It offers the best balance of speed, massive context windows, and reasoning. It is significantly cheaper than frontier models like GPT-5.5 or Claude Opus 4.7. This lets me scale the volume of my agentic thoughts without scaling my debt.
Try This Monday: The Cost-Routing Prompt

You do not need to build a Linux box today to start saving money. You just need to stop defaulting your team's workflows to the most expensive model available.
Another tip: check out plugins for Claude like Superpowers or Oh-My-Claude-Code. These tools offer intelligent model selection, letting you toggle between high-reasoning and high-efficiency models based on the task.
If you are building automated workflows, use this prompt to audit your current AI usage:
You are an AI Systems Architect specializing in FinOps and cost-control for agentic workflows.
I am currently running the following automated tasks using [INSERT YOUR CURRENT EXPENSIVE MODEL, e.g., GPT-5.5 or Claude Opus 4.7]:
1. [TASK 1: e.g., Summarizing daily standup notes]
2. [TASK 2: e.g., Formatting user stories into a specific JSON schema]
3. [TASK 3: e.g., Analyzing complex code architecture for security flaws]
Evaluate each task strictly on its required reasoning depth.
For each task, provide:
- The required capability (Basic formatting, extraction, or deep reasoning?)
- A recommendation: Can this be downgraded to a fast/cheap model (like Gemini 3 Flash or Claude Sonnet 4.6) or does it strictly require a frontier model?
- A one-sentence justification for the recommendation.
Be ruthless. Default to recommending the cheaper model unless deep, multi-step logical deduction is required.
The Final Verdict
We spend so much time in the agile community arguing about velocity, completely ignoring the infrastructure that lets our teams work.
If you are a delivery leader in 2026, your job isn't just running meetings and unblocking dependencies. Your job is managing the flow of value through increasingly automated systems. If those systems are financially toxic or compromise privacy, the value doesn't matter.
Stop treating AI like a luxury SaaS subscription. Start owning your infrastructure.
Go look at your API usage charts tomorrow morning. Inspect the data.
Your move.
Continue Your Journey
AI Development for Non-Technical Builders: Stop paying the API tax and learn to orchestrate your own local and cloud AI workflows without needing a computer science degree.
The Second Brain: Discover how to securely store and query your own coaching knowledge locally, keeping your data out of public training pools.